Zählen, was zählt: Unterscheidung von Datenlecks und Aggregationen im Fall „Synthient“

➤Summary
Abstract
Öffentliche Narrative verwechseln häufig tatsächliche Sicherheitsverletzungen mit aggregierten Sammlungen von Zugangsdaten, die aus Malware-Logs und historischen Vorfällen stammen. Anhand der 2025 erfolgten Ergänzungen durch „Synthient“ in Have I Been Pwned (HIBP) unterscheidet dieses Papier zwischen (a) Stealer-Log-Sammlungen (183 Millionen eindeutige E‑Mail‑Adressen, die HIBP hinzugefügt wurden) und (b) Credential‑Stuffing‑Kompilationen (≈2 Milliarden eindeutige E‑Mail‑Adressen und ≈1,3 Milliarden eindeutige Passwörter, die zu Pwned Passwords hinzugefügt wurden). Es wird gezeigt, wie Letztere in Medienberichten häufig als einzelne, zeitnahe „Mega‑Breaches“ fehlinterpretiert werden. Wir ordnen dieses Phänomen historisch (z. B. Collection #1 2019; die „MOAB“-Kompilation 2024), analysieren das Ökosystem von Stealer‑Logs und Aggregationen (Telegram, Foren, Darknet) und quantifizieren, wie „tägliche“ Open‑Source‑Funde Schlagzeilenwerte erreichen können. Abschließend wird ein Taxonomie‑ und Messrahmen für künftige Berichterstattung vorgeschlagen.
Einleitung
Im Oktober–November 2025 hat HIBP zwei unterschiedliche Synthient‑Datensätze aufgenommen:
- Stealer‑Log Threat Data — 183 Mio. eindeutige E‑Mail‑Adressen, abgeleitet aus Infostealer‑Malware‑Logs; und
- Credential‑Stuffing Threat Data — ≈2 Mrd. eindeutige E‑Mail‑Adressen (zusätzlich ≈1,3 Mrd. eindeutige Passwörter), zusammengeführt aus Credential‑Stuffing‑Listen mehrerer Quellen.
Diese beiden Datensätze haben unterschiedliche Bedeutungen und Evidenzstufen. Dennoch fasste die Berichterstattung sie teilweise als einen einzigen „Riesendatenleck“-Vorfall zusammen, was zu Missverständnissen führte. Dieses Papier zeigt, warum Begriffsvermischung („Breach“ vs. „Collection“), Skalierungsinflation (Zeilen vs. eindeutige Einträge) und die Intransparenz des Ökosystems Lücken zwischen öffentlicher Wahrnehmung und empirischer Realität erzeugen.
Definitionen: Breach vs. Collection
Breach (Systemkompromittierung). Ein Ereignis, bei dem ein spezifischer Dienst, eine Organisation oder eine Plattform kompromittiert wurde, was zu unautorisiertem Zugriff auf deren Daten führt. Artefakte eines Breachs beinhalten typischerweise kohärente Tabellen, Metadaten und Kontext‑Signale, die die Daten mit dem kompromittierten Dienst und einem Zeitrahmen verknüpfen.
Stealer‑Log‑Sammlung. Eine Zusammenstellung von Zugangsdaten, die von Endpunkten durch Informations‑stahler‑Malware exfiltriert wurden. Diese Logs spiegeln befallene Geräte wider, nicht serverseitige Datenbanken; sie sind heterogen formatiert (Cookies, Sitzungsdaten, dienstspezifische Credentials) und werden von Aggregatoren weiterverbreitet.
Credential‑Stuffing‑Liste („Combo‑List“). Cross‑Site‑Kompilationen von E‑Mail:Passwort‑Paaren, die aus früheren Leaks und Stealer‑Dumps zusammengestellt wurden, mit dem Ziel automatisierter Wiederverwendung (Replay) gegen andere Dienste. Diese Listen sind kein Beleg für ein frisches serverseitiges Leck.
Historische Präzedenzfälle der Fehlinterpretation
Collection #1 (2019)
„Collection #1“ wurde weithin als „Mega‑Breach“ bezeichnet, doch die primäre Analyse betonte, dass es sich um eine große Aggregation für Credential‑Stuffing handelte: ~2,6 Milliarden Zeilen komprimierten sich nach Deduplizierung auf ~773 Millionen eindeutige E‑Mail‑Adressen und ~1,16 Milliarden eindeutige E‑Mail‑Passwort‑Paare. Medien‑Narrative vermischten wiederholt „Breach“ und „Collection“.
„Mother of All Breaches“ (MOAB, 2024)
Berichte zitierten teilweise 26 Milliarden „Datensätze“, doch die Korpus war eine massive Mehrquellen‑Kompilation, kein einzelnes Ereignis. Die Zahlen banden heterogene Quellen und Zeiträume ein; Eindeutigkeit und Aktualität lagen weit unter den Schlagzeilenwerten.
Synthient (2025)
HIBP nahm zwei verschiedene Synthient‑Datensätze auf: Stealer‑Logs (183 Mio. eindeutige E‑Mails) und eine separate Credential‑Stuffing‑Aggregation (2 Mrd. eindeutige E‑Mails). Einige Medien kondensierten dies fälschlich zu einem „Gmail‑Leak“ mit Millionen betroffener Google‑Konten; Google wies das zurück, da kein Plattform‑Breach vorlag.
Das Leak‑Sammlung‑Ökosystem: Quellen, Flüsse, Akteure
Kanäle.
- Telegram: Eine dominante Distributionsschicht für Stealer‑Logs und „Log Clouds“; unterstützt sowohl Exfiltration (Bots) als auch Wiederverkauf und Re‑Posting.
- Web‑Foren & Paste‑Seiten: Werben, kopieren oder veröffentlichen Combolists und stealer‑geschützte Archive.
- Darknet‑Marktplätze / Threat‑Communities: Verkaufen frische Logs und Bundles, typischerweise vor der breiteren Zirkulation.
Akteure.
- Primary sellers (betreiben private Channels/Shops);
- Aggregators (verschmelzen, normalisieren und redistributeiren; leaken manchmal Subsets zur Reputationserhöhung);
- Traffers (Malware‑Distributions‑Affiliates, die die Upstream‑Lieferung speisen);
- Indexer/Curatoren (z. B. Forschungseinrichtungen oder TI‑Anbieter, die ingest, dedupe und labeln).
Datenfluss. Endpunkt‑Kompromittierung → Log‑Exfiltration → Private Verkäufe → Sekundärverkauf/Aggregation → Öffentliche „Combo“-Zirkulation → Archivierung/Indexierung durch Dritte (Forscher, TI‑Anbieter, HIBP). Je weiter entfernt von der Quelle, desto höher die Duplizierung und desto geringer die zeitliche Auflösung.
Fallstudie: Synthient 2025
Stealer‑Log Datensatz (183 Mio. Eindeutige)
HIBP’s Eintrag dokumentiert eine kuratierte Ergänzung von 183 Mio. eindeutigen E‑Mail‑Adressen, die aus Infostealer‑Malware‑Logs stammten. Dies ist kein Plattform‑Breach, sondern ein multi‑quelliger Endpunkt‑Exfiltrationskorpus, normalisiert für Benachrichtigung.
Credential‑Stuffing‑Aggregation (≈2 Mrd. Eindeutige; ≈1,3 Mrd. Passwörter)
Ein zweiter Synthient‑Eintrag konsolidiert ≈2 Mrd. eindeutige E‑Mail‑Adressen aus mehreren Quellen und trägt ≈1,3 Mrd. eindeutige Passwörter zu Pwned Passwords bei. Dieser Korpus stammt ausdrücklich aus früheren Leaks und für Replay‑Angriffe verwendeten Listen. Die beiden Datensätze sind zu unterscheiden und dürfen nicht vermischt werden.
Dynamiken der Falschberichterstattung
Mehrere Artikel stellten beides irrtümlich als einen „Gmail‑Leak“ dar. Google betonte, dass kein solcher Plattform‑Breach stattgefunden habe; die Daten stammen aus verstreuten, teils historischen Quellen.
Messgrößen sind entscheidend: Zeilen, Datensätze, Eindeutige und Einheiten
Ein wiederkehrendes Problem ist die Ambiguität der Einheit:
- Zeilen/Rows (Roh‑Einträge in Textdateien)
- Eindeutige E‑Mail‑Adressen (nach Deduplizierung)
- Eindeutige E‑Mail:Passwort‑Paare (noch kleiner als Zeilen; weiterhin durch Wiederverwendung aufgebläht)
- Eindeutige Passwörter (Pwned Passwords)
- Eindeutige Nutzer, die einem spezifischen Dienst zuzuordnen sind (oft deutlich kleiner als die Schlagzeilenzahlen)
Forschungen zeigen, dass Credential‑Stuffing‑Korpora stark dupliziert und zeitlich heterogen sind, sodass „Milliarden von Datensätzen“ nach Normalisierung oft auf einige hundert Millionen eindeutige E‑Mails schrumpfen.
Quantifizierung „Panik vs. Realität“: 183 Mio. im Verhältnis zu einem einzelnen Tag
Darknetsearch.com stellte eine Datenprobe mit ~30 GB Plain‑Text‑Zugangsdaten im Format site:email:password bereit. Bei Stichproben vergleichbarer Zeilen (≈59 Bytes inkl. Newline) entsprechen 30 GB etwa ~545 Millionen Zeilen für diesen Tag:
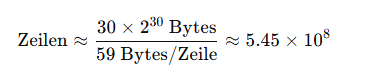
Interpretation.
- Dies sind Zeilen, nicht eindeutige Einträge. Deduplizierung (nach E‑Mail bzw. nach E‑Mail:Passwort‑Paar) reduziert die Anzahl erheblich — ein Effekt, der in HIBP‑Normalisierungen sichtbar wird. Dennoch zeigt diese Rechnung, wie einzelne Tage intensiver Open‑Source‑Sammlung Volumina erreichen können, die in der gleichen Größenordnung wie Medien‑Schlagzeilen liegen (mehrere hundert Millionen), und erklärt, warum „1–2 Milliarden“ leicht erreicht werden, wenn mehrere Quellen und Tage aggregiert werden.
Warum Lücken bestehen: Eine wissenschaftliche Analyse
Terminologie‑Drift und mediale Anreize
„Breach“ ist ein attention‑maximierendes Label. Aggregationen werden gern als „Mega‑Lecks“ umgedeutet, während methodische Vorbehalte (Duplikate, zeitliche Heterogenität) in Headlines vernachlässigt werden.
Intransparenz des Ökosystems
Die Lieferkette (Endpunkt‑Exfiltration → Verkauf → Aggregation → öffentliche Freigabe) ist komplex und absichtlich verschleiert. Journalisten und Öffentlichkeit sehen selten die Provenienz und die Dedupe‑Mathematik; deshalb werden Roh‑Zeilen oft für eindeutige Opfer gehalten.
Datenhandel und Reputationsekonomie
Verkäufer und Aggregatoren profitieren von der Behauptung von Neuheit und Umfang; Forscher und Medien erhalten Sichtbarkeit durch große Zahlen. Strukturell entstehen so Verzerrungen zugunsten maximalistischer Behauptungen.
Mess‑ und Normalisierungsprobleme
Die Harmonisierung heterogener Formate aus verschiedenen Stealer‑Familien ist technisch anspruchsvoll; exakte Deduplizierung erfordert robuste Normalisierung (z. B. Case‑Folding, Unicode‑NFKC, Parser‑Heuristiken). Akademische Arbeiten zu kompromittierten Anmeldeinformationen heben die hohe Wiederverwendungsrate und Recycling‑Effekte hervor.
Jenseits von Telegram: Quellen und Aktualitätsstufen
Frisch / privat:
- Geschlossene Darknet‑Marktplätze und Invite‑only‑Channels (frischeste Stealer‑Logs; teuer nach Recency/Target Value).
Semi‑öffentlich:
- Telegram „Log Clouds“ und Aggregator‑Channels; häufiges Re‑Posting und Merging; teils Paywalls, viele Spiegel.
Öffentlich / Archiv:
- Clear‑Web‑Foren, Paste‑Seiten und Spiegel, wo historische Combolists und „Greatest‑Hits“ erscheinen; maximale Duplizierung, minimale Aktualität.
Dieser Gradientenansatz erklärt, warum dieselbe Person wiederholt in Listen auftauchen kann, ohne dass es sich um neue Opfer handelt — es ist Re‑Packaging.
Synthient‑Architektur als Meta‑Aggregator
Synthient beschreibt in einem öffentlichen Blog eine Architektur mit multi‑account Telegram‑Crawlern, einem entkoppelten Downloader/Parser, Nachrichten/Attachment‑Korrelation und ClickHouse‑basierter Deduplizierung anhand von Datei‑Hashes. Das ist typisch für moderne TI‑Ingest‑Stacks, die auf mehreren Ebenen deduplizieren müssen, um aussagekräftige eindeutige Zählungen zu erhalten — genau der Grund, warum HIBP‑Kurationen von Roh‑„Milliarden“ abweichen.
Einschränkungen
Dieses Papier analysiert öffentliche Beschreibungen der Datensätze (HIBP‑Einträge, Anbieter‑Blogs, Presse) und beansprucht nicht, Rohdaten zu besitzen. Größenumrechnungen (z. B. 30 GB → ~545 M Zeilen) sind explizit als Schätzungen auf Basis der Stichproben‑Zeilenlänge gekennzeichnet; die tatsächliche Eindeutigkeit hängt von der angewandten Dedupe‑Methodik ab.
Schlussfolgerung
Die Diskrepanz zwischen Panik und Realität in der Berichterstattung über Zugangsdatenleaks ist primär ein Problem von Messung und Provenienz. Synthient’s 2025‑Beiträge zu HIBP — zwei unterschiedliche Datensätze mit unterschiedlicher Bedeutung — bieten ein klares Labor: Wenn wir Stealer‑Log‑Sammlungen von Credential‑Stuffing‑Kompilationen trennen und eindeutige Zählungen (statt Roh‑Zeilen) fordern, ändert sich die Narrative. Historische Fälle (Collection #1, MOAB) bestätigen: „Milliarden“ sind zumeist das Ergebnis von Aggregation über Zeit und Quellen, nicht ein frisches Plattform‑Breach. Eine gemeinsame Taxonomie — Breach vs. Collection, Rows vs. Uniques, und Aktualitätsklassen über Telegram, Darknet‑Marktplätze und öffentliche Spiegel — ermöglicht präzisere wissenschaftliche und journalistische Aussagen.
Discover how CISOs, SOC teams, and risk leaders use our platform to detect leaks, monitor the dark web, and prevent account takeover.
🚀Explore use cases →
